offline
- Fil

- Legendarni građanin

- Pridružio: 11 Jun 2009
- Poruke: 16586
|
- 52Ovo se svidja korisnicima: N1k0l4, Springfield, Brano, dr_Bora, Taxista, Ričard, FarscapeFan, SSpin, mcrule, NoOneEver Dreams, Sorelag, Riddler, dee jay zeka, DenisUA98, Dusan, NIx Car, markomirtic, ivance95, Sass Drake, nikola9896, bluewortex, vasa.93, Mila_90, hellingen, CyberSrbin032, Jimmy4, pipiishale, _Sale, TwinHeadedEagle, Melisa Joldic Curtovic, Melody, DreamingStar, helen1, brankosmarkovic, kaivmair, DzoniB, Padishah, Ado Doa, ana.stubnja, mpman, kamenko2010, Pelagija, sfi.zarada, E.L.I.T.E., duki2207, angelas, jsglenssa, klodovik, srbijankatopic, mayab., Filodendron, Knežević
Registruj se da bi pohvalio/la poruku!
[0] PROLOG
Moj prijatelj je ovih dana odbranio diplomski rad i ja sam bio zadužen za stvari tehničkog karaktera: statistička obrada podataka, fensi grafikoni, pisanje Abstracta na engleskom, i ostale konsultacije/poslovi tehničkog karaktera.
Rad je istraživačkog tipa; osobe ženskog pola su popunjavale upitnik i ja sam dobijene podatke uneo u softver SPSS i izvršio neophodne statistike za diplomski rad.
Kako se SPSS redovno koristi kod istraživačkih radova, bilo da su u pitanju maturski, seminarski, diplomski ... i ostali radovi, rešio sam da iskustva podelim sa vama.
Konkretno, u ovome članku ću opisati step-by-step proceduru izrade ovakvog diplomskog rada, uključujući koncipiranje same ankete, formiranje hipoteza, unosa podataka u SPSS matricu, analize podataka preko SPSS-a (naravno, biće obrađene samo one funkcije koje su mi bile neophodne za izradu rada) do prezentiranja rezultata (i samim tim prihvatanja ili odbacivanja početnih hipoteza).
Tema je krajnje interesantna i golicava  pa mi je jedan od ciljeva da, pored tematike tehničkog tipa, nešto naučimo i o metodama kontracepcije i svežih rezultata iz prakse. Rezultati su zanimljivi. Tako da --> stay tuned pa mi je jedan od ciljeva da, pored tematike tehničkog tipa, nešto naučimo i o metodama kontracepcije i svežih rezultata iz prakse. Rezultati su zanimljivi. Tako da --> stay tuned 

Slika: Verzija SPSS-a sa kojom su rađene analize
* Napomena: softver je komercijalan i verzija softvera postoji i za Windows
[1] UVOD
Pre nego što krenemo sa upitnikom i tehničkom pričom, autor diplomskog rada treba da definiše problem i ciljeve istraživanja koji će biti obuhvaćeni u njegovom istraživačkom radu.
U ovom diplomskom radu problematika istraživanja se odnosi na analizu faktora koji imaju uticaj na učestalost korišćenja kontraceptivnih metoda kod žena generativnog perioda.
Definisani ciljevi rada su sledeći:
1. Utvrditi u kom obimu se upotrebljava kontracepcija u ispitivanoj populaciji žena
2. Utvrditi koji faktori doprinose upotrebi kontracepcije
3. Utvrditi da li postoje negativni stavovi prema upotrebi kontracepcije
Hipoteze istraživanja
Iz zadatih ciljeva rada proistekle su i sledeće hipoteze:
H1- obim upotrebe kontracepcije u ispitivanoj populaciji je veći od 60%
H2- starost žena ima pozitivan efekat na upotrebu kontracepcije
H3- obrazovanje žene i njenog partnera/supružnika ima pozitivan uticaj na upotrebu kontracepcije
H4- frekvencija upotrebe kontracepcije je veća kod žena urbanog područja u odnosu na žene ruralnog područja
H5-vrsta emotivne veze je bitan faktor koji određuje upotrebu kontracepcije
H6- ostvareno potomstvo ima pozitivan uticaj na upotrebu kontracepcije
H7- broj željene djece ima pozitivan uticaj na upotrebu kontracepcije
H7- učestalost seksualnih odnosa ima pozitivan uticaj na upotrebu kontracepcije
H8- u ispitivanoj populaciji postoje negativni stavovi prema upotrebi kontracepcije
H9- nuspojave i zablude o kontraceptivnim tabletama imaju veći uticaj na njihovu upotrebu u odnosu na njihove korisne efekte
Malo i o varijablama istraživanja
U istraživanju se razlikuju nezavisne i zavisne varijable. Nezavisne varijable su: godine starosti, mesto stalnog boravka, obrazovanje, stalna partnerska veza u trenutku istraživanja, vrsta emotivne veze u trenutku istraživanja, postojanje potomstva, broj djece, učestalost seksualnih odnosa. Zavisne varijable su upotreba kontracepcije, učestalost upotrebe i odabir kontraceptivnog sredstva.
[2] FORMIRANJE UPITNIKA
Dakle, kao metod istraživanja, korišćen je anonimni upitnik koji je posebno sastavljen za prikupljanje podataka u ovom istraživanju.
[4] FORMIRANJE MATRICE
======================================================================
Napomena:
* [url=https://www.mycity.rs/must-login.png [ OVDE ][/url] možete preuzeti primer matrice koju sam ograničio na 20 opservacija (20 popunjenih upitnika).
======================================================================
Matrica u SPSS-u se formira na osnovu upitnika. Znači, svako pitanje u upitniku mora biti na odgovarajući način preslikano na matricu. U SPSS-u razlikujemo dva osnovna pogleda: Variable View i Data View.
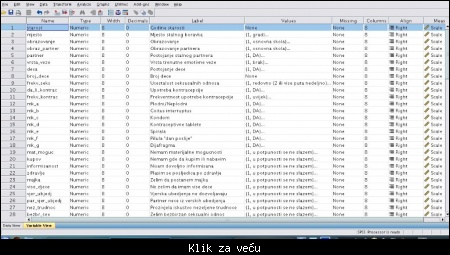
Slika: Variable View - prikaz promenljivih
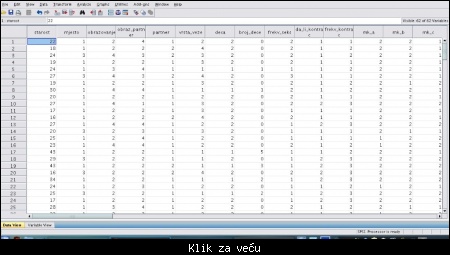
Slika: Data View - prikaz podataka
Najpre moramo da definišemo parametre vezane za promenljive. Pri tome treba obratiti pažnju da:
--> pitanje u upitniku kod koga se bira samo jedan odgovor - predstavlja jednu promenljivu
(na primer, pitanje 2 iz upitnika "Mesto stalnog boravka" )
--> pitanje u upitniku kod koga se može odabrati više odgovora - ne može da čini jednu promenljivu, već ga razbijamo na podceline (tj. podpromenljive).
(na primer, pitanje 12 iz upitnika "Koji metod kontracepcije koristite")
Uporedite upitnik i strukturu matrice (uključiti Variable View) da biste videli ovu logiku definisanja promenljivih. Svaka promenljiva se definiše u redovima, a parametri koji su vezani za tu promenljivu nalaze se u kolonama. Ime (Name) treba odabrati što kraće i što jasnije jer će ono biti prikazano u Data View; opis (Label) treba da bude detaljan za odabranu promenljivu; vrednosti (Values) promenljive su diskretnog numeričkog tipa; upitnik je bio takav da nisu tolerisana zabušavanja , znači da su žene morale je da popune sve podatke, stoga nema "nedostajućih vrednosti" (Missing).
Ono što može da buni, kod definisanja parametra Values, je kvantifikacija podataka, čija je priroda kvalitativna (al' sam ga sročio).
--> Dakle, sve ćemo odgovore ispitanica (koji su većinom kvalitativni) prikazati brojem !
Ovde ćemo razlikovati 4 situacije:
a) od ispitanice se očekuje neki unos (na primer, pitanje 1. "Godine starosti")
--> ovde nema problema sa preslikavanjem na brojnu vrednost jer se godine izražavaju brojem
b) od ispitanice se očekuje zaokruživanje jednog odgovora (na primer, pitanje 2. "Mesto stalnog boravka")
--> svakoj opciji ćemo dodeliti po jednu numeričku vrednost
Da ne bi mnogo filozofirali, slika će da objasni ovaj princip:
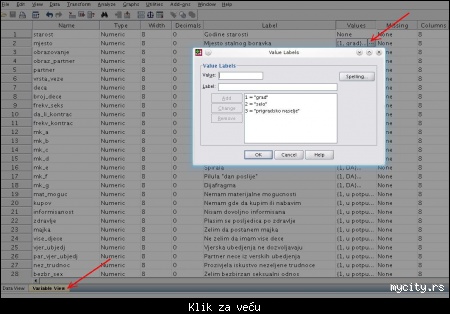
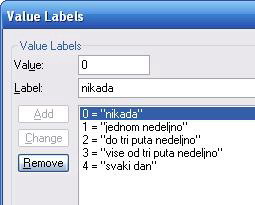
Slika: definisanje numeričkih vrednosti za odgovore
Prvo se postarajmo da smo u Variable View. Potom kliknimo na Values i kada je pojavi kvadratić, kliknimo na njega. Otvoriće se novi prozor (u fokusu) gde definišemo preslikavanje odgovora na numeričku vrednost. Kada povežemo oznaku i broj, treba kliknuti na Add.
c) ispitanica može da zaokruži više odgovora (na primer, pitanje 12. vezano za izbor metode kontracepcije)
--> pitanje nećemo predstaviti sa jednom promenljivom, već sa više tzv. DA/NE promenljivih. Svaka mogućnost koja može biti zaokružena, biće predstavljena sa posebnom promenljivom.
Evo slike i za ovu situaciju:

Slika: primer razlaganja na više promenljivih sa vrednostima DA i NE (tj. 1 i 2)
Malo edukacije: ovde nije pomenuta "apstinencija" koja takođe predstavlja metodu kontracepcije i to jedinu 100% uspešnu (drug je verovatno ovo sveo na pitanje 9 pod c)). Po jednom istraživanju najčešća metoda kontracepcije kod srba je takozvani "coitus interruptus" ili "prekinuti snošaj". Videću da ubacim još jedan rad koji pokazuje FAIL ovih metoda, tj. kolika je šansa da žena zatrudni ukoliko pribegava specifičnim metodama kontracepcije. Koliko me sećanje služi, impulsivni muškarci ne smeju pribegavati C.I. metodi jer ne mogu da kontrolišu ejakulaciju. Oni koji, pak, mogu a pri tome su neiskusni ~20% šanse je da će partner zatrudneti. Kod iskusnih se ovaj procenat značajno smanjuje. Samo teorijski i uz grubu apstrakciju posmatrano, ko želi potpuno "prirodan" metod kontracepcije drugar preporučuje kombinaciju: praćenje plodni/neplodni dani + apstinencija za vreme plodnih dana + prekinut snošaj.
Nego, vratimo se mi na matricu 
d) Numerički odgovori koji su zasnovani na Likertovoj skali (1-5). Ako se sve ispratili do sada, i ovo bi trebalo da bude jasno. Videti sliku:
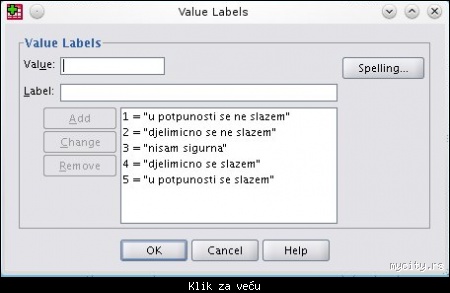
Slika: prikaz odgovora po Likertovoj skali
OK, sad bi trebalo da znate da formulišete sve promenljive (varijable) i odredite sve parametre sa lakoćom.
Sada je vreme da se prebacimo na Data View. U Data View, u kolonama se nalaze promenljive, a u redovima opservacije (odnosno jedan red = jedna opservacija = jedna ispitanica).
Možda ovo opet deluje pomalo nejasno, pa ćemo proći kroz primer (da ne bih mnogo filozofirao):

Slika: prikaz dela opservacije u Data View
OK, nahvatali smo prvu tetu s reda. Da vidimo kako ćemo tumačiti podatke (otvorite u isto vreme matricu i sliku upitnika):
--> Ima 22 godine, živi u gradu, ide u srednju skolu, partner joj ide na faks, ima stalnog partnera, u dugoj je emotivnoj vezi, nema dece, broj dece je 0 (primetite bug ) , rijetko ima seksualne odnose, koristi kontracepciju, pri tome koristi je uvek, i to kondom i pilulu.
(naravno, reverznom metodom se na osnovu upitnika popunjava matrica ! )
To je to. Očekuje vas naporan posao ukucavanja svih opservacija....................
* Učitavanje matrice, čuvanje matrice, generisanje statistika, ... i sve druge aktivnosti će biti logovane u Output prozoru. Kada ga ugasite, SPSS će vas upitati da li želite da sačuvate promene. Ovo pitanje nije vezano za samu matricu već samo za Output prozor. Dakle, ako ne sačuvate promene to neće da utiče na matricu.
[5] STATISTIKA
* Ukliko već niste, preuzmite i otvorite rad (DOC datoteku) koji sam linkovao na početku članka
Za potrebe ovoga rada, najpre će nam trebati deskriptivna statistika, deo oko analize frekvenci. Obratite pažnju na poglavlje: Rezultati istraživanja i potpoglavlje 3.1 - Karakteristike ispitivane populacije, grafikon 2.
Dakle, potrebno je odabrati meni: Analyze --> Descriptive Statistics --> Frequencies...
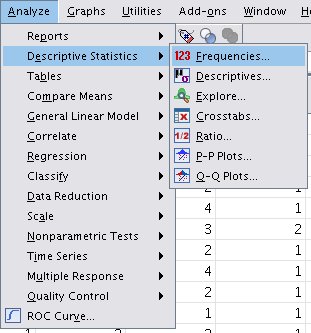
Slika: odabir menija za analizu frekvenci
Klikom na strelicu udesno biramo promenljive koje će biti analizirane:
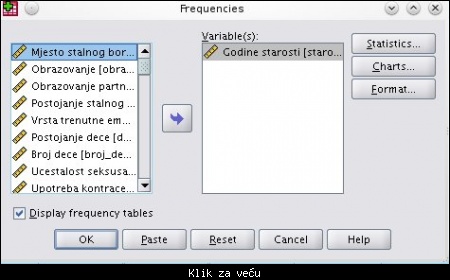
Slika: odabir promenljive za analizu
Klikom na dugme Charts... dobija se sledeći prozor, gde biramo opciju Histograms i treba štriklirati opciju With normal curve (da bi se dobila linija normalne raspodele na histrogramu).
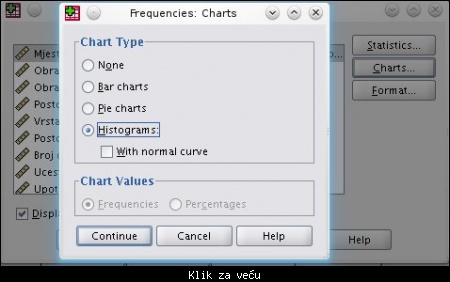
Slika: odabir histograma, kao načina prikazivanja podataka
Rezultate analize softvera možete videti u tzv. Output prozoru. U njemu se prate sve akcije, počevši od čuvanja matrice, učitavanje nove datoteke, izvršene analize i druge izvršene operacije.
Bitno je da nema missing values jer se ovaj parametar pokazuje da li neke vrednosti nedostaju u matrici (ovo može poslužiti kao mini reper za kontrolu unosa podataka u matricu).
N predstavlja veličinu uzorka;
Tabelu treba analizirati na sledeći način: broj anketiranih devojaka koje imaju 16 godina je 3; procentualno 1.4% od ukupnog broja anketiranih devojaka i kumulativni procenat predstavlja zbir svih ostalih procenata u koloni do tekućeg reda. Ovaj parametar se iskoristio u radu da se konstatuje da je npr. uzrast ispitanica od 16 - 20 god. zastupljen sa 11.7 % .
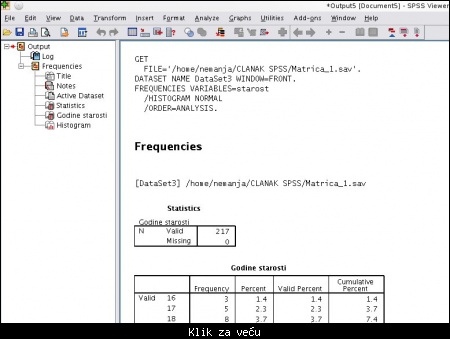
Slika: Output prozor i rezultat analize frekvenci
Na prozoru Output prikazuje se i grafikon koji smo odabrali:
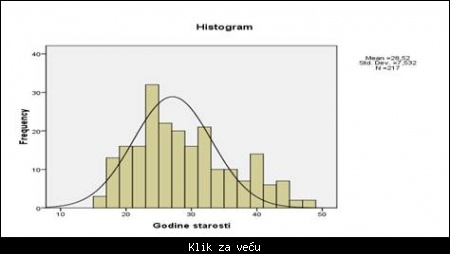
Slika: prikaz histograma koji je iskorišten za rad
Na grafikonu 3 je odabrana opcija Bar Charts sa definisanim procentima kao vrednostima grafika:
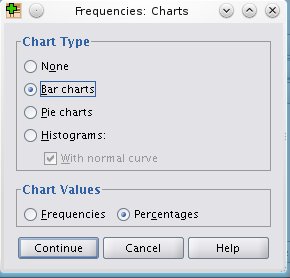
Slika: prikaz definisanja parametara za Bar Chart
Kako na lak način da ubacite sve ove grafikone i tabele u vaš seminarski/maturski/diplomski rad?
--> U prozoru Output, na beloj (slobodnoj) površini kliknite desnim tasterom miša i odaberite opciju Export... Pojaviće se sledeći prozor:
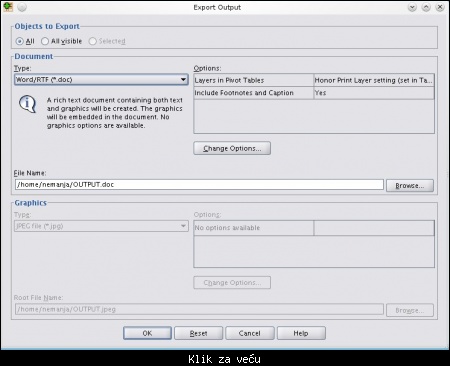
Slika: prozor za izvoz (export) sadržaja prozora Output
[url=https://www.mycity.rs/must-login.png prilažem i datoteku koju sam dobio sa exportovanjem. Dakle, pomoću LibreOffice-a, OpenOffice-a ili nekog drugog tekst procesora (tipa Microsoft Office Word 2010) možete otvoriti datoteku i jednostavno u rad iskopirati tabele ili grafikone koji su vam od značaja.
Grafike je moguće formulisati i pojedinačno, bez statistika, a na osnovu podataka iz matrice. Za te potrebe služi meni Charts. Chart Builder predstavlja moćni Wizard koji služi za definisanje informacija koje će se pojaviti u grafiku. Druga, jednostavnija opcija je Legacy Dialogs, na primer:
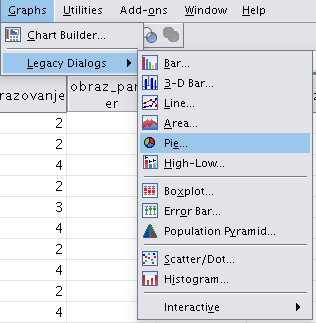
Slika: odabir stavke Legacy Dialogs

Slika: odabraćemo grupu slučajeva
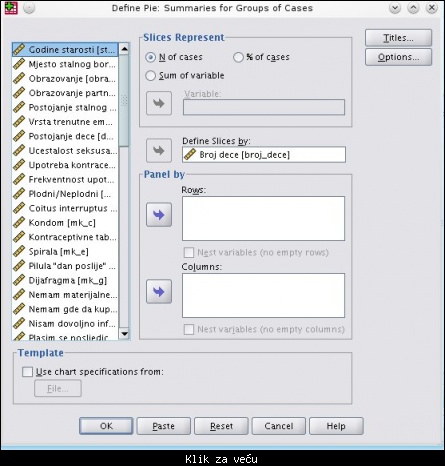
Slika: Parčiće grafika (slices) ćemo odabrati po promenljivoj "broj dece"
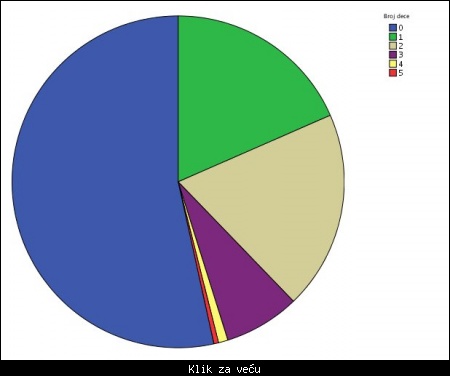
Slika: rezultirajući grafik u osnovnoj formi
Dakle, u ovoj situaciji pojaviće se samo grafik bez statistika, i to bazična verzija grafika. Dvostrukim klikom na grafik moguće je urediti taj grafik, na primer dodavanje procenata na parčiće, definisanje drugog tipa grafika, dodavanje dimenzije, izmena legende i drugo.
Kroz čitava potpoglavlja 3.1 i 3.2 iskorišteni su ovi, do sad navedeni statistički principi, samo sa drugim promenljivima.
U potpoglavlju 3.3 - Faktori koji utiču na upotrebu kontracepcije i negativni stavovi o kontracepciji, koristi se takozvani Hi-kvadrat test (Chi Square Test) koji će biti upotrebljen iz upoređivanja promenljivih (Crosstabulation).
Odaberite meni i stavke kao sa sledeće slike:
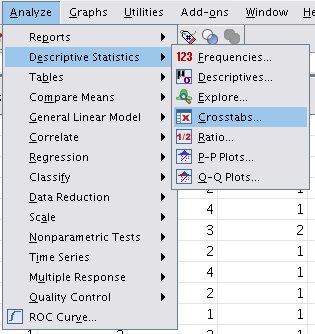
Slika: odabir stavke Crosstabs...
Želimo da vidimo kakvo je stanje sa upotrebom kontracepcije u odnosu na mesto stalnog boravka:
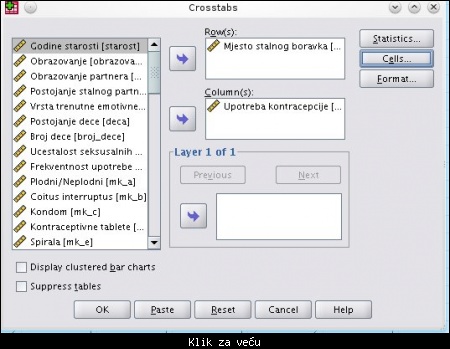
Slika: definisanje promenljivih u redu i koloni
Kliknimo na dugme Statistics...; Označiti stavke kao sa slike i potvrditi sa Continue.
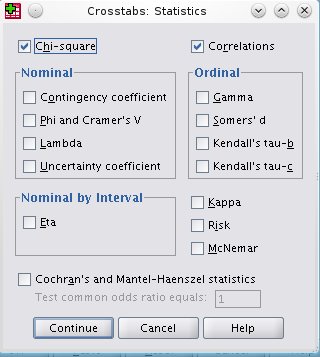
Slika: dijalog Statistics...
Zatim treba kliknuti na dugme Cells jer želimo uključiti i prikaz procenata; označiti parametre kao sa slike:
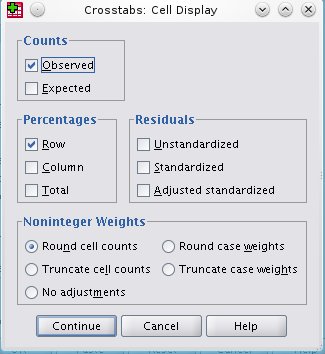
Slika: dijalog Cell Display...
Pojaviće se sledeći output prozor sa rezultatima analize. Uporediti sa tabelom u radu:
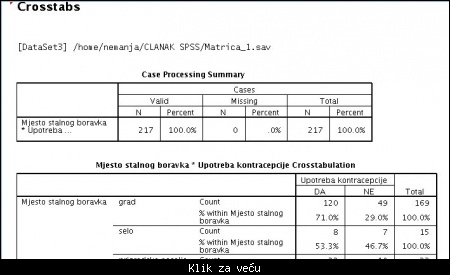
Slika: prikaz rezultata u Output prozoru
Iz jedne druge analize vidimo deo koji se tiče Hi-kvadrat testa:
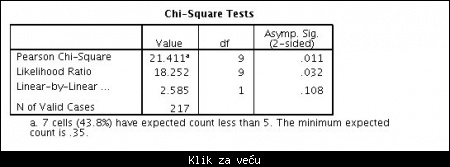
Slika: odeljak koji se tiče Chi Square testa
Parametri koji treba da se nalaze u vašem radu su:
Value --> predstavlja vrednost statistike
df --> predstavlja broj stepeni slobode (degrees of freedom). U literaturi se označava i sa "n".
sig --> predstavlja značajnost statistike (significance); U literturi se označava sa "p".
Najpre, hipoteze za Hi-kvadrat test nezavisnosti se postavljaju na sledeći način (u opštem slučaju):
Ho: Dve kategoričke promenljive su nezavisne (ovo je tzv. nulta hipoteza).
Ha: Dve kategoričke promenljive su zavisne (povezane).
Odlučivanje za odbacivanje ili prihvatanje hipoteza se vrši na osnovu značajnosti. Naime, ako je "p" <= 0.05, tada je test statistički značajan i odbacuje se nulta hipoteza (Ho). Dakle:
- Ukoliko je vrednost parametra "p" <= 0.05 hipoteza Ha se prihvata, a odbacuje Ho.
- Ukoliko je vrednost parametra "p" > 0.05 hipoteza Ho se prihvata, a Ha se odbacuje
Što se tiče frekventne analize ajtema, vrši se idenično kao analiza frekvneci:
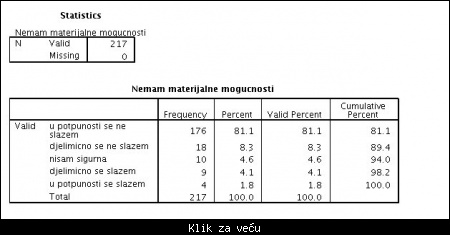
Slika: prikaz jedne frekventne analize ajtema
Za dalju diskusije oko prihvatanja ili odbacivanja hipoteza na osnovu ovih statističkih rezultata i neslaganja rezultata sa postojećim arhivskim rezultatima našeg područja, treba pročitati deo u radu koji nosi naziv Diskusija. 
PS Odlučio sam se da postavim beta verziju rada jer je profesor izbacio 15 strana rada (fol, bio je glomazan). Pošto od viška informacija glava ne boli, bolje je okačiti betu. 
Nadam se da će ovo koristiti nekome.
Do sledećeg članka,

|